
В предыдущей части мы занимались общими вопросами построения данных часов. В этой части займемся звуковыми семплами, включая которые в нужной последовательности можно получить любое значение текущего времени от 0:00 до 23:00 в голосовом формате.
Итак, преступим.
Для того, чтобы озвучить значения времени от 0 часов до 20, нужно 21 слово («ноль», «один», «два» … «двадцать»). Но, чтобы сказать 21, 22 и 23, новые слова нам уже нужны. Можно использовать уже имеющиеся в распоряжении: «двадцать» + «один», «двадцать» + «два» и «двадцать» + «три». Идея, надеюсь, понятна.
Чтобы текущее время звучало более-менее вменяемо, после значений 1 и 21 необходимо говорить «час» (двадцать один час), после 2, 3, 4, 22, 23 подходит слово «часа» (четыре часа, двадцать два часа), и после остальных значений, а именно 0, 5-20 слово «часов» (ноль часов, десять часов). Все сказанное попробую представить в виде таблицы:
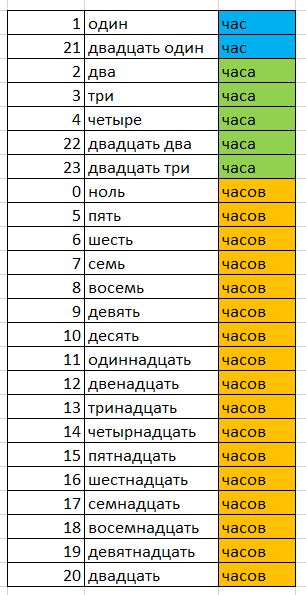
Таким образом, нам необходимо три варианта слова: «час», «часа», «часов».
Перейдем к минутам. Проделывая все те же операции, получаем следующую таблицу:
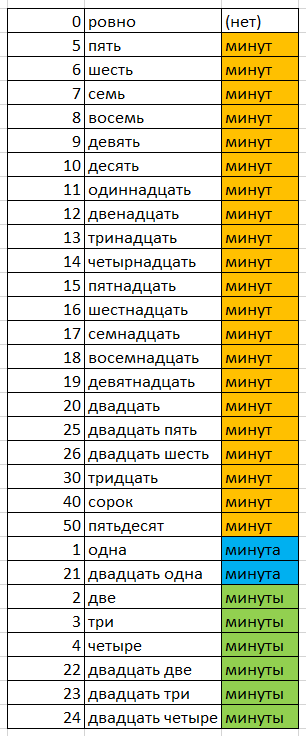
Здесь так же три варианта завершающего слова, а именно «минут», «минута» и «минуты». Если текущее время что-то типа 21:00, то хочу, чтоб часы говорили «двадцать один час, ровно», а не «двадцать один час, ноль минут».
Займемся теперь самими цифрами. Для экономии места во FLASH-памяти хотелось бы использовать те же слова для озвучивания и значений часа, и минут. Но тут не совсем все гладко. Для случая 20:20 «двадцать часов, двадцать минут» и подобных все отлично, но для 21:21 видна проблема, нельзя сказать «двадцать один час, двадцать один минута». Таким образом, для некоторых значений цифр необходимо два варианта, в мужском и женском роде. Этих «особых» цифр не так и много, а именно «1» и «2», что не может не радовать.
В итоге нам необходимо записать следующие слова:
"ноль", "один", "одна", "два", "две", "три", "четыре", "пять", "шесть", "семь", "восемь", "девять", "десять", "одиннадцать", "двенадцать", "тринадцать", "четырнадцать", "пятнадцать", "шестнадцать", "семнадцать", "восемнадцать", "девятнадцать", "двадцать", "тридцать", "сорок", "пятьдесят", "ровно", "час", "часов", "часа", "минут", "минута", "минуты".
Ну и так как у нас есть внешний термодатчик, то почему бы не озвучивать и его? В итоге добавим еще несколько слов:
"минус", "градус", "градуса", "градусов", "температура на улице".
Итак, все подготовительные операции завершены, можно приступать к озвучиванию. Вариант с записью своего голоса отпадает по эстетическим соображениям, поэтому на ум сразу приходят разные речевые синтезаторы. Гугл.Тетка и ей подобные мне не понравились. В результате наткнулся на этот синтезатор, насколько понял называется RHVoice. Доступно несколько голосов и больше всего понравился Anna, его и решил использовать. Устанавливается все это хозяйство как-то мутно, поэтому будет не лишним написать небольшую инструкцию. Операция проводилась на Windows 7 x64. На XP наблюдались проблемы.
Для успешной установки необходимо скачать 3 файла: основной пакет, языковой пакет и голос, причем везде выбираем «Версия, совместимая с SAPI5». После скачивания у нас должно образоваться файла:
- RHVoice-v0.5-setup.exe
- RHVoice-language-Russian-v2.0-setup.exe
- RHVoice-voice-Russian-Anna-v1.0-setup.exe
Устанавливаем их в указанном порядке. Весь процесс установки занимает считанные секунды. Затем можно пойти в Панель управления => Специальные возможности => Распознавание речи => Преобразование текста в речь, выбрать пункт «Anna» и проверить, как она говорит (там может быть пункт «Microsoft Anna», это не то).
Далее, нам нужна программа, которая будет на вход получать наш текст, и, используя установленный синтезатор, сохранять его в wav-файл. Для этого подойдет программа, которая называется Balabolka. Она умеет много чего, в том числе воспроизводить текстовый файл с помощью установленных на компе речевых синтезаторов и сохранять текст в wav-файл, то, что нам и нужно! Собственно, записываем наши слова, при необходимости обрабатываем их в каком-нибудь аудиоредакторе и получаем готовые семплы.
Тут есть небольшая хитрость, некоторые слова синтезатор произносит криво, и чтоб это хоть как-то это исправить слово нужно писать «не совсем правильно». Например, «пятьдесят» ну ни как не хотела говорить нормально, а когда написал «пядесят» все стало норм. Некоторые слова исправляются пробелом посреди слова, некоторые приходилось писать в составе предложения, чтобы нормально звучала интонация. Так же есть специальные управляющие символы, которыми можно указать ударение и интонацию, но я с ними не разбирался. В конце статьи будет размещена ссылка на архив с моими wav-семплами.
Фух, половина дела завершено. Поговорим теперь о том, как предоставить доступ к нашей коллекции семплов AVR-ке. Да легко, повесим внешнюю spi флешку и все. Для этого нам нужно разработать формат хранения семплов на флешке. На этом этапе нам надо определиться с частотой дискретизации и разрядностью ЦАП-а. С разрядностью особо не поиграешься, в моем случае для R-2R делителя 8 бит будет оптимальным значением. А вот частоту дискретизации выбрал ~22 КГц. Теперь аудиоредактором конвертируем наши семплы в соответствующий вид: Моно, 22 КГц, 8 бит.
Теперь нам нужна еще одна программа, которая из полученных семплов будет собирать дамп. И ее придется писать самим. В ходе долгих (или не очень долгих, давно было, уже не помню) размышлений появилась вот такая структура:
/* структура, хранящая информацию об одном семпле */
struct SAMPLE_STRUCT
{
uint32_t start; //адрес начала семпла
uint32_t lenght; //длина семпла
};
/* структура, которая хранит информацию о всех семплах */
struct FLASH_HEADER
{
SAMPLE_STRUCT sample_0; //"ноль"
SAMPLE_STRUCT sample_1m; //"один"
SAMPLE_STRUCT sample_1w; //"одна"
SAMPLE_STRUCT sample_2m; //"два"
SAMPLE_STRUCT sample_2w; //"две"
SAMPLE_STRUCT sample_3; //"три"
SAMPLE_STRUCT sample_4; //"четыре"
SAMPLE_STRUCT sample_5; //"пять" и т.д.
SAMPLE_STRUCT sample_6;
SAMPLE_STRUCT sample_7;
SAMPLE_STRUCT sample_8;
SAMPLE_STRUCT sample_9;
SAMPLE_STRUCT sample_10;
SAMPLE_STRUCT sample_11;
SAMPLE_STRUCT sample_12;
SAMPLE_STRUCT sample_13;
SAMPLE_STRUCT sample_14;
SAMPLE_STRUCT sample_15;
SAMPLE_STRUCT sample_16;
SAMPLE_STRUCT sample_17;
SAMPLE_STRUCT sample_18;
SAMPLE_STRUCT sample_19;
SAMPLE_STRUCT sample_20;
SAMPLE_STRUCT sample_30;
SAMPLE_STRUCT sample_40;
SAMPLE_STRUCT sample_50;
SAMPLE_STRUCT sample_rovno; //"ровно"
SAMPLE_STRUCT sample_chas; //"час"
SAMPLE_STRUCT sample_chasov; //"часов"
SAMPLE_STRUCT sample_chasa; //"часа"
SAMPLE_STRUCT sample_minut; //"минут"
SAMPLE_STRUCT sample_minuta; //"минута"
SAMPLE_STRUCT sample_minuty; //"минуты"
SAMPLE_STRUCT sample_bell; //звук, который звучит перед сообщением
SAMPLE_STRUCT sample_alarm; //звук будильника (будильник так и не сделал)
SAMPLE_STRUCT sample_minus; //"минус"
SAMPLE_STRUCT sample_gradus; //"градус"
SAMPLE_STRUCT sample_gradusa; //"градуса"
SAMPLE_STRUCT sample_gradusov; //"градусов"
SAMPLE_STRUCT sample_temperatura_na_ulitse; //"температура на улице"
};
/* Собственно, дамп флешки */
struct FLASH_DUMP
{
//заголовок
struct FLASH_HEADER header;
//сами семплы, друг за другом,
// в порядке, представленном в FLASH_HEADER
char pcm_data[FLASH_SIZE - sizeof(FLASH_HEADER)];
} flash_dump_s;
В чем состоит идея: дамп разбит на две части: заголовок и сами данные. Заголовок состоит из 40-ка записей по sizeof(SAMPLE_STRUCT) = 2*sizeof(uint32_t) = 64 байта. Каждая запись хранит информацию о адресе начала текущего семпла, и о его длине. После заголовка идут сами семплы, склееные вместе друг за другом. Если мы хотим проиграть слово «три», то нам нужно обратиться к 5-ой записи (счет с нуля), которая будет находиться по адресу 5*sizeof(SAMPLE_STRUCT) = 320, прочитать sizeof(SAMPLE_STRUCT) = 64 байта, узнать адрес начала start и длину семпла lenght, в котором записано слово «три», перейти по адресу start и прочитать lenght байт. Затем прочитанные данные выплюнуть в ЦАП и наслаждаться звучанием слова «три». Осталось дело за малым, реализовать все это)) Описывать программу я не буду, так как отрыв ее, я испытал тихий ужас от своего старого кода. Кину в конце статьи как есть. В планах конечно же все переделать и сделать все правильно)) Но это когда-нибудь потом.
На этом пока все, в следующей части возьмемся за железо наших часов.
программа для создания дампа https://yadi.sk/d/9aVGuQHY3NXhjN семплы расположены в VoiceBuilder\bin\Debug\
Читать продолжение.